
Adam Kinney, Head of Machine Learning bei Mixpanel
04. September 2019
Take me to the English version of this article.
Mixpanel ist eines der beliebtesten Datentools für große Unternehmen, ebenso wie für Startups. In San Francisco haben wir mit dem Head of Machine Learning, Adam Kinney, und mit CEO Amir Movafaghi über die Roadmaps für Machine Learning gesprochen, und welche Rolle Mixpanel zukünftig in der Nutzeranalyse spielen will.
- In diesem Artikel erfahrt ihr:
- Warum Kausalzusammenhänge das nächste große Ding bei ML sind.
- In welchen Bereichen Machine Learning für Adam das größte Potenzial hat.
- Wie Mixpanel seine Produktteams am Innovation Loop ausrichtet.
- Wie Adam als Engineering Lead mit seinen Teams Roadmaps plant.
- Wann ihr ein eigenes Data Science-Team im Unternehmen braucht.
Am wohlsten fühlt sich Adam Kinney, wenn er nicht die klügste Person im Raum ist. Das sagt Adam zumindest über sich selbst, als wir ihn im Mixpanel-Headquarter in San Francisco zum Interview treffen. Hinter dieser Selbstbeschreibung stecken zwei Dinge. Zum einen ist der Head of Machine Learning and Analysis von Mixpanel offenkundig eine sehr bescheidene Person. Zugleich offenbart Adam mit seiner Aussage über sich noch eine zweite Qualität: Die Bereitschaft, jeden Tag dazu zu lernen und eigene Ideen und Vorschläge ergebnisoffen zur Diskussion zu stellen.

Wahrscheinlich sind diese Fähigkeiten in kaum einem Bereich von größerem Nutzen als bei Künstlicher Intelligenz und Machine Learning. Sowohl Wissenschaft als auch Unternehmen beginnen gerade erst damit zu verstehen, wie diese Technologie so eingesetzt werden kann, dass für die Nutzer echter Mehrwert entsteht. Doch am Horizont zeichnet sich bereits ab, wozu zukünftige Versionen Künstlicher Intelligenz in der Lage sein werden. Und bei aller Bescheidenheit: Adam, der bereits bei Google und Twitter wichtige Rollen in der statistischen Analyse hatte, glaubt fest daran, dass Mixpanel bei dieser Entwicklung ein Wörtchen mitreden kann. Für ihn bedeutet das, ständig abzuwägen zwischen großen, visionären Ideen, die über Monate reifen und entwickelt werden müssen, und pragmatischen Use Cases, die in zweiwöchigen Sprintzyklen bei Mixpanel umgesetzt werden können.

Über Adam
Als Leitmotiv hat sich für Adam dabei das bekannte Zitat über den Computer als “bicycle for our minds” von Steve Jobs erwiesen. So, wie der Computer das Arbeiten immens beschleunigt hat, glaubt Adam, dass Machine Learning den Menschen in die Lage versetzen wird, Dinge noch schneller und effizienter zu erledigen als vorher.
Besonders geprägt hat Adam in dieser Hinsicht seine Zeit bei Schibsted Media, einem großen norwegischen Medienhaus, das neben einigen Tageszeitungen eine Reihe von Kleinanzeigenportalen betreibt.
„Von so etwas wie einer General Intelligence sind wir noch ziemlich weit entfernt.“
Adam war auf dem besten Weg, eine Bilderbuchkarriere im Silicon Valley hinzulegen. Dem Abschluss in Statistik in Stanford war 2006 direkt ein erster Job bei Google gefolgt. Dort erlebte er, wie der Tech-Gigant langsam aber sicher zur führenden Instanz in Sachen Maschinellem Lernen wurde, erinnert sich Adam: “Ich war eine der ersten Personen bei Google, die keinen Hintergrund als Entwickler hatte, sondern aus der statistischen Analyse kam. Ich konnte mit Big Data-Tools und Technologien arbeiten, von denen die meisten Leute noch gar nichts gehört hatten.”



Mit diesen Erfahrungen im Gepäck wechselte Adam 2010 zu Twitter und baute dort ein 18-köpfiges Team für Data Science auf. Während dieser Zeit traf er erstmals Amir Movafaghi, den heutigen CEO von Mixpanel, der bei Twitter damals für Finance verantwortlich war. Nach Jobs bei zwei der einflussreichsten Tech-Companies unserer Zeit, noch dazu im boomenden Bereich Data Science, hätten Adam alle Türen im Silicon Valley offen gestanden. Doch er entschied völlig anders: “Ich hatte nie außerhalb der Bay Area gearbeitet und wollte nochmal was Neues sehen.” Er ging das Risiko, nahm ein Angebot von Schibsted an und zog mit der Familie über den Atlantik nach Norwegen.
Machine Learning beim Medienunternehmen
Bei dem 1839 gegründeten Verlag lernte Adam eine andere Arbeitskultur und -umgebung kennen: “Bei Google sind es die Entwickler, die den Laden schmeißen. Das ist sehr beeindruckend, aber es kann auch einschüchtern, wenn man keinen solchen Hintergrund hat.” Bei Schibsted Media traf Adam auf Redakteure und Vertriebler, deren Jobs sich ausgerechnet durch die Produkte seiner beiden früheren Arbeitgeber massiv verändert hatten. Für den im Silicon Valley geprägten Tech-Enthusiasten begann ein Lernprozess: “Anfangs hatte ich die ziemlich naive Sicht, News-Seiten komplett zu personalisieren und von Algorithmen erstellen zu lassen. Weg mit den Redakteuren und dem ganzen Zeug! Aber als ich gesehen habe, wie diese Leute arbeiten und wie Prozesse in einer Redaktion funktionieren, wurde mir klar, wo der wirkliche Wert liegen würde”, erinnert sich Adam.


Sein Fokus verschob sich: Statt die Arbeit von Menschen durch Technologie zu ersetzen, ging es nun darum, Prozesse zu verbessern, um seinen Kollegen die Arbeit wieder zu erleichtern. Für die Kleinanzeigenportale von Schibsted entwickelte er Features, die den Nutzern mit Bilderkennung halfen, Verkaufsanzeigen einfacher und schneller zu erstellen. Die Redaktion unterstützte er mit einem Tool, das Artikeln mittels Texterkennung automatisch Tags zuwies, so dass die Redakteure das nicht mehr selbst machen mussten und wieder mehr Kapazitäten für andere Tätigkeiten hatten.
Im Sommer 2018 endete dann das Abenteuer Schibsted Media für Adam. Sein ehemaliger Twitter-Kollege Amir Movafaghi hatte gerade den Job als CEO beim Analyse-Tool Mixpanel übernommen. Als Adam ihm dazu mit einer Nachricht gratulierte, schrieb Amir prompt zurück: “Wir sollten uns mal treffen, wir haben hier ein paar spannende Dinge vor.”
Der Innovation Loop
Mixpanel hatte sich seit seiner Gründung im Jahr 2010 durch Suhail Doshi und Tim Tefren zu einem führenden Tool für die Analyse von Nutzerverhalten entwickelt. Nun sollte der nächste Schritt folgen: Mixpanel sollte mehr können als Metriken liefern, um Datentrends zu erkennen. Als Basis dafür diente Mixpanel der so genannte Innovation Loop werden, erklärt uns CEO Amir: “Dieser Loop ist keine Erfindung von uns. Es ist ein Zyklus, dem innovative Unternehmen seit vielen Jahren folgen. Er bildet jetzt die Säulen für unsere Produktentwicklung.” Die fünf Schritte sind wie folgt.
- Erhebung: Am Anfang steht eine saubere Datensammlung aus den unterschiedlichen Kanälen und Plattformen.
- Visualisierung: Grafiken und Diagramme bringen lange Datenreihen in Formate, die von den Teams verstanden und verarbeitet werden können.
- Analyse: Nun kann man die Daten lesen und versucht, Zusammenhänge und Muster zwischen den einzelnen Datenpunkten zu erkennen.
- Interpretation: Im nächsten Schritt geht es darum, diese Zusammenhänge richtig zu interpretieren und zu verstehen, warum die Daten so sind wie sie sind. Dafür bildet man Hypothesen und testet diese.
- Anleitung: Daraus ergeben sich konkrete Handlungsoptionen. Man möchte ein bestimmte Veränderung in den erreichen, zum Beispiel “Mehr Newsletter-Anmeldungen”. Anhand der Daten weiß man, an welchen Schrauben man dafür drehen muss. Daraus ergeben sich neue Datenpunkte und der Kreis schließt sich.
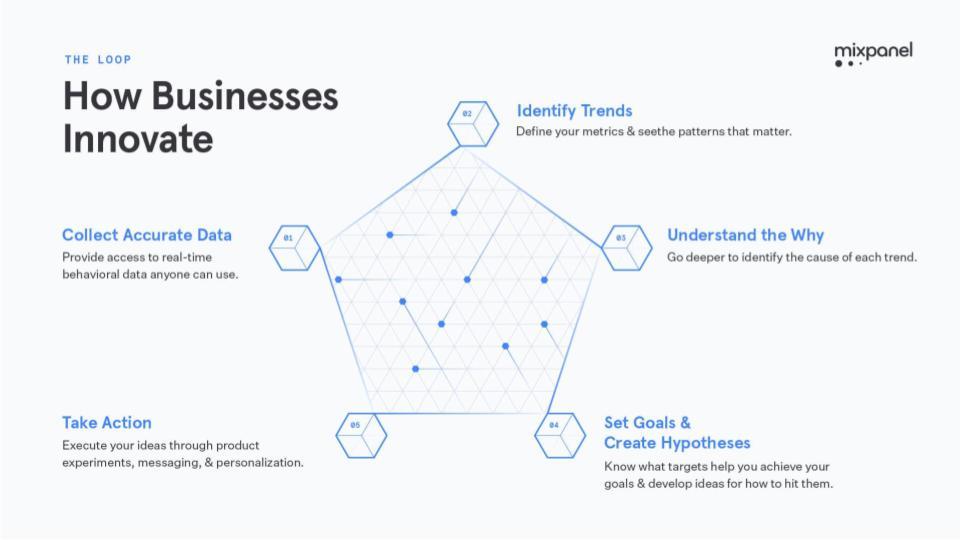
Das Ziel von Mixpanel ist es, diesen Prozess maximal zu beschleunigen. Jedes Team ist einer dieser Säulen zugeordnet, erklärt Amir: “Wir wollen Unternehmen in die Lage versetzen, Ideen effizient zu testen, damit sie schnell herausfinden, was funktioniert und was nicht. Wer das schafft, ist agil, disruptiv und hat dadurch einen immensen Wettbewerbsvorteil. Auf diese Weise haben Firmen wie Slack oder Airbnb schnell einen Product-Market-Fit gefunden, neue Ideen ausprobiert und die Großen herausgefordert. Und auch für größere Unternehmen ist es von Vorteil, wenn sie innovativ bleiben und ihre vorhandenen Ressourcen richtig einsetzen können.”

Als Head of Machine Learning and Analysis kommt Adam mit seinem Team vor allem an den Schritten drei und vier, Analyse und Interpretation, ins Spiel. Machine Learning bei Mixpanel ist immer Datenanalyse, aber nicht alles in der Analyse ist automatisch Machine Learning, so dass Adam hier eng mit seinen Kollegen im Analyseteam zusammenarbeitet.
Ein paar Features des Machine Learning Teams sind stand-alone, zum Beispiel die “Anomaly Detection”, erklärt Adam. Wenn man einen ungewöhnlichen Ausschlag in einer Metrik hat, kriegt man automatisch eine Benachrichtigung dazu, um sofort Maßnahmen einleiten zu können. Ein anderes Feature nennt sich “Predict”. Damit werden bestimmte Vorhersagen über mögliches Nutzerverhalten getroffen und mit einer Wahrscheinlichkeit versehen. So kann man Nutzern zum Beispiel einen Rabattcode schicken, bevor ein Produkt gekauft wird.
Kurz- und langfristige Road-Maps
Adams Gedanken kreisen fast rund um die Uhr um Möglichkeiten und Grenzen von Machine Learning und wie man die Technologie für die Produkte von Mixpanel einsetzen kann. In diversen Google-Docs (“Davon habe ich einen ganzen Haufen.”) sammelt er seine Ideen und arbeitet sie weiter aus. Die kleineren, schnell umsetzbaren Initiativen gibt er direkt in die Teams.
Dabei ist es Adam wichtig, dass seine Ideen genau wie alle anderen diskutiert und herausgefordert werden: “Wenn ich als erster meine Idee zu einem Problem vorstelle, kann es passieren, dass sich alles nur noch darum dreht. Darum treffen sich alle Beteiligten in einem großen Raum, wo jeder drei Ideen raushauen kann. Je verrückter, desto besser. Alle Vorschläge sammeln wir auf Post-Its und clustern sie in einem Spreadsheet. Dann votet jeder auf einer Skala von 1 bis 5, was unseren Kunden den größten Nutzen bringen würde. Manche meiner Ideen landen dabei vorne, aber oft werden sie einkassiert, was ich großartig finde.”
Dieser Prozess hilft dem Team, eine grobe Priorisierung zu entwickeln. Die konkrete Roadmap definieren die Teams selbst. Die Engineering Leads setzen die Leitplanken und achten darauf, dass sich die Teams nicht verzetteln, sagt Adam: “Wir sind nicht sehr prozesslastig. Mir ist es wichtig, dass es für die Projekte mit der höchsten Priorität auch eine klare Richtung gibt. Ich bin immer bereit, den Kurs zu wechseln, wenn wir neue Nutzerdaten oder andere Informationen kriegen. Aber es ist wichtig, den Fokus zu behalten und lieber wenige Dinge sehr gut als viele mittelmäßig zu machen.”


Die größeren Initiativen teilt Adam zunächst mit den anderen Engineering Leads und den jeweiligen Produktmanagern und holt sich Feedback. “Das ist ein Prozess, der sich über Wochen hinziehen kann. Bevor die erste Zeile Code geschrieben wird, tausche ich mich intensiv mit dem Produktmanager aus, bis wir komplett auf einer Wellenlänge darüber sind, wie ein solches Projekt aussehen kann.” Ein Beispiel für eine solche große Initiative ist der Versuch, eines der fundamentalen Probleme der statistischen Analyse zu lösen: Das Aufdecken von Kausalzusammenhängen zwischen zwei oder mehreren Variablen.
Ursache-Wirkung: Das nächste große Ding
Das Kernproblem ist, dass eine Maschine die Daten schnell auswerten kann. Aber diese Daten zu interpretieren und die daraus die richtigen Schlussfolgerungen zu ziehen, dafür braucht es sehr anspruchsvolle Algorithmen. Nutzerverhalten ist eine komplexe Sache. Warum kaufen bestimmte Menschen etwas in einem Shop und andere nicht? Warum brechen manche User einen Onboarding-Prozess an einem Punkt ab und andere nicht? Wieso geht die Nutzungszeit in der App runter, seit ein neues Feature online ist? Um das exakt zu verstehen, braucht es nicht nur Daten, sondern auch das empathische Verständnis von Menschen. In der Produktentwicklung werden Entscheidungen heutzutage überwiegend auf Basis von Nutzerdaten getroffe. Ein Risiko dabei ist, Korrelation mit Kausalität zu verwechseln. Das führt zu Fehlinterpretationen und letztlich auch zu falschen Produktentscheidungen.
Dieses Risiko möchte Adam mit Mixpanel reduzieren, erklärt er: “Ich habe das in meiner Zeit als Data Scientist selbst erlebt. Wenn ich in die Daten geguckt habe, dachte ich, ich hätte eine Erklärung für ein bestimmtes Phänomen gefunden. Aber wenn wir einen A/B-Test gemacht haben, war auf einmal nichts mehr da. Das ist sehr frustrierend.” Die Schwierigkeit ist dabei, die Drittvariablen zu kontrollieren.
Ein bekanntes Beispiel dafür ist das Phänomen, dass Menschen ein umso höheres Einkommen haben, je größer ihre Schuhgröße ist. Doch es sind nicht große Füße, die einen zwangsläufig zum Traumgehalt führen. Die Wahrheit hinter dieser Statistik ist eine andere: Männer werden tendenziell besser bezahlt als Frauen und haben biologisch bedingt oft größere Füße. Sobald man die Statistik nach Geschlecht auflöst, verschwindet die Korrelation. Diese Statistik lässt sich leicht auflösen, weil die Drittvariable “Geschlecht” klar definiert ist. Aber was ist, wenn es um komplexe Eigenschaften wie Nutzerverhalten geht?



Adam nennt ein (konstruiertes) Beispiel aus dem E-Commerce: Personen, die häufig Produktreviews schreiben, kaufen häufiger in einem Online-Shop, als Personen, die keine Reviews schreiben. Wenn das stimmt und es einen kausalen Zusammenhang gibt, wäre es sinnvoll, die Nutzer dazu zu bringen, mehr Reviews zu schreiben, um den Umsatz zu steigern. Es könnte aber auch sein, dass es eine Gruppe von Hardcore-Nutzern gibt, die einfach den Online-Shop unfassbar gut finden und insgesamt aktiver als andere Nutzer sind. Darum gibt es zwar eine Korrelation zwischen Kaufbereitschaft und dem Schreiben von Reviews, aber keinen kausalen Zusammenhang. Dann wäre es sinnvoller, etwas für die Kundenbindung zu tun, und weniger oder durchschnittlich aktive Nutzer zu Hardcore-Nutzern zu machen. Je nachdem, welche Erklärung richtig ist, müssen andere Features entwickelt, andere Nutzer angesprochen werden.
Doch um herauszufinden, welchen Weg hier der richtige ist, müsste ein Shop-Anbieter tatsächlich sehr viel Aufwand über einen langen Zeitraum betreiben. Es braucht valide Kriterien für Hardcore-Nutzer, um sie von anderen Usern abzugrenzen. Entwickler müssten ein funktionierendes Feature bauen, das die User anregt, mehr Reviews zu schreiben. Dann müsste das Produktteam über einen längeren Zeitraum beobachten, bei welchen Nutzern tatsächlich mehr Reviews zu mehr Umsatz führen und diese Informationen mit Kontrollgruppen gegenprüfen, um nicht erneut auf eine Scheinkorrelation reinzufallen.
“Allein damit kann man ein halbes Jahr verbringen, um dann festzustellen, dass man falsch gelegen hat.”
Und in diesem Beispiel ist noch nicht berücksichtigt, dass es in der Realität nicht nur eine, sondern zehn mögliche Variablen geben könnte, die diesen Effekt verursachen. Wer kein großes Data Science Team und entsprechende Ressourcen in der Entwicklung hat, kann solche Analysen nicht stemmen.
Tools wie Mixpanel können diesen Prozess erleichtern, glaubt Adam. “Kausalzusammenhänge sind das nächste große Ding im Machine Learning. Die Idee ist, mit statistischen Methoden ein Modell zu schaffen, dass die wahrscheinlichsten Erklärungen für ein bestimmtes Nutzerverhalten vorhersagt. Natürlich wird man damit nie bei 100 Prozent Genauigkeit landen. Aber wenn man in der Lage ist, von zehn möglichen Ursachen die drei wahrscheinlichsten zu isolieren, wäre schon sehr viel gewonnen”, erklärt Adam. Es würde Entscheidungsprozesse vereinfachen und Produktteams helfen zu priorisieren. Außerdem könnten Unternehmen ihre Ressourcen für Datenanalyse besser planen. Denn der Aufbau eines Teams für Data Science ist keine triviale Sache, sagt Adam.

Wann man ein Data Science-Team braucht
“Ich habe selber in diesem Bereich gearbeitet und verstehe eine Menge der Probleme und Frustrationen in diesem Job. Ich glaube, dass viele Unternehmen zu früh damit anfangen, eigene Data Scientists einzustellen. Aber damit diese Experten wirklich Probleme lösen können, brauchen sie eine Infrastruktur mit hochwertigen Daten. Die sind gerade bei kleineren und early-stage Unternehmen noch nicht da. Das bedeutet: Ein Data Scientist kann zwar Probleme erkennen und erklären, wie man sie lösen könnte. Aber die Entwickler haben keine Zeit dafür. Das sorgt für Frust und ein Gefühl der Ohnmacht.”
Viel wichtiger ist es, die Daten vom Start weg sauber einzusammeln und in einem eigenen Data Warehouse zu loggen. “Das kriegt ein guter Backend-Entwickler alleine hin, in dem er ein paar Cloud-Services zusammenwirft.” Erst, wenn es im Unternehmen niemanden mehr gibt, der bestimmte Fragen zu den Daten mit Bordmitteln beantworten kann, wird es Zeit jemand Neues dazuzuholen. Für Adam ist es eine Frage der Priorisierung: “Wenn man die Wahl hat, einen Full-Time Data Scientist einzustellen, oder ins bestehende Entwicklerteam zu investieren, und die ein einfaches Analytics-Setup bauen zu lassen, lohnt es sich wahrscheinlich mehr, letzteres zu tun.”
Aber auch für Data Scientists hat Adam einen Ratschlag: Sie sollten in der Lage sein, mit den Entwicklern in ihrer Sprache zu sprechen.
“Ich habe im Studium mehr Programmierkurse belegt, als ich gemusst hätte, und das war sehr wichtig für mich.”
Womit wir wieder bei Adams Statement sind, dass er nicht die klügste Person im Raum sein möchte: Wer als Data Scientist langfristig erfolgreich sein möchte, sollte es den anderen Leuten im Raum nicht zu leicht zu machen, schlauer zu sein als man selbst.
Dieser Text und die Bilder entstanden im alten Office von Mixpanel in der Howard Street. Inzwischen ist das Unternehmen in ein neues Büro gezogen. Alle Digitale Leute-Texte aus San Francisco gibt es hier zu lesen.




